import pyvista
from diffdrr.visualization import drr_to_mesh, img_to_mesh
pyvista.start_xvfb()
def df_to_mesh(drr, df):
pts = []
for idx in tqdm(range(len(df))):
rot = torch.tensor(df.iloc[idx][["alpha", "beta", "gamma"]].tolist())
xyz = torch.tensor(df.iloc[idx][["bx", "by", "bz"]].tolist())
pose = convert(
rot.unsqueeze(0),
xyz.unsqueeze(0),
parameterization="euler_angles",
convention="ZXY",
).cuda()
with torch.no_grad():
source, _ = drr.detector(pose, None)
pts.append(source.squeeze().cpu().tolist())
return *img_to_mesh(drr, pose), lines_from_points(np.array(pts))
def lines_from_points(points):
"""Given an array of points, make a line set"""
poly = pyvista.PolyData()
poly.points = points
cells = np.full((len(points) - 1, 3), 2, dtype=np.int_)
cells[:, 1] = np.arange(0, len(points) - 1, dtype=np.int_)
cells[:, 2] = np.arange(1, len(points), dtype=np.int_)
poly.lines = cells
return poly.tube(radius=3)
plotter = pyvista.Plotter()
ct = drr_to_mesh(drr.subject, "surface_nets", 150, verbose=False)
plotter.add_mesh(ct)
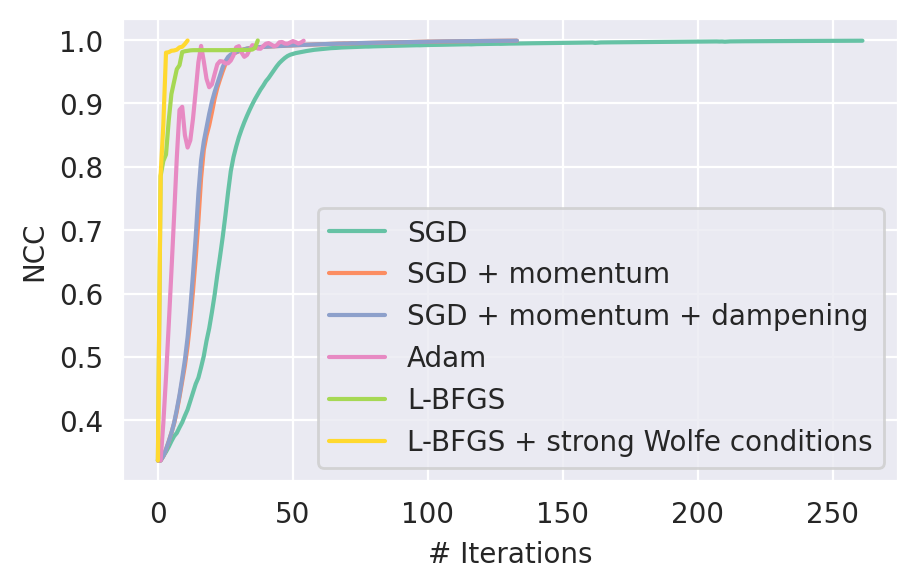
# SGD
camera, detector, texture, principal_ray, points = df_to_mesh(drr, params_base)
plotter.add_mesh(camera, show_edges=True, line_width=1.5)
plotter.add_mesh(principal_ray, color="#66c2a5", line_width=3)
plotter.add_mesh(detector, texture=texture)
plotter.add_mesh(points, color="#66c2a5")
# SGD + momentum
camera, detector, texture, principal_ray, points = df_to_mesh(drr, params_momentum)
plotter.add_mesh(camera, show_edges=True, line_width=1.5)
plotter.add_mesh(principal_ray, color="#fc8d62", line_width=3)
plotter.add_mesh(detector, texture=texture)
plotter.add_mesh(points, color="#fc8d62")
# SGD + momentum + dampening
camera, detector, texture, principal_ray, points = df_to_mesh(
drr, params_momentum_dampen
)
plotter.add_mesh(camera, show_edges=True, line_width=1.5)
plotter.add_mesh(principal_ray, color="#8da0cb", line_width=3)
plotter.add_mesh(detector, texture=texture)
plotter.add_mesh(points, color="#8da0cb")
# Adam
camera, detector, texture, principal_ray, points = df_to_mesh(drr, params_adam)
plotter.add_mesh(camera, show_edges=True, line_width=1.5)
plotter.add_mesh(principal_ray, color="#e78ac3", line_width=3)
plotter.add_mesh(detector, texture=texture)
plotter.add_mesh(points, color="#e78ac3")
# L-BFGS
camera, detector, texture, principal_ray, points = df_to_mesh(drr, params_lbfgs)
plotter.add_mesh(camera, show_edges=True, line_width=1.5)
plotter.add_mesh(principal_ray, color="#a6d854", line_width=3)
plotter.add_mesh(detector, texture=texture)
plotter.add_mesh(points, color="#a6d854")
# L-BFGS + line search
camera, detector, texture, principal_ray, points = df_to_mesh(drr, params_lbfgs_wolfe)
plotter.add_mesh(camera, show_edges=True, line_width=1.5)
plotter.add_mesh(principal_ray, color="#ffd92f", line_width=3)
plotter.add_mesh(detector, texture=texture)
plotter.add_mesh(points, color="#ffd92f")
# Ground truth
camera, detector, texture, principal_ray = img_to_mesh(drr, gt_pose)
plotter.add_mesh(camera, show_edges=True, line_width=1.5)
plotter.add_mesh(principal_ray, color="black", line_width=3)
plotter.add_mesh(detector, texture=texture)
# Render the plot
plotter.add_axes()
plotter.add_bounding_box()
plotter.export_html("registration_runs.html")